A few months ago I rebuilt my router on an espressobin and got the itch to overhaul the rest of my homelab. While I could pick up some post-market AmaFaceGooSoft equipment for a typical high-power x86 lab, I decided to put the devops mantra of a distributed, fault-tolerant architecture to work and see how far I could get with lots of small, cheap, low-power machines instead.
In a nutshell, I'm running ~20 ARM-based single-board computer cluster that drives a container-scheduled application runtime (Nomad) backed by distributed storage (GlusterFS) with service discovery in place (Consul) to provide me with a platform to run all my applications and services with a mostly self-configured HTTPS (Let's Encrypt) front end (Traefik). Vault, Prometheus, and a bunch of supporting applications are also deployed in order to make operating this setup secure, easy, and eminently scalable.
I've diverged from this architecture since time of writing (2018). See this post with some updates; which are mostly replacing Traefik with consul-template, adding a wireguard mesh, and migrating to ODroid HC4 machines for 64-bit support.
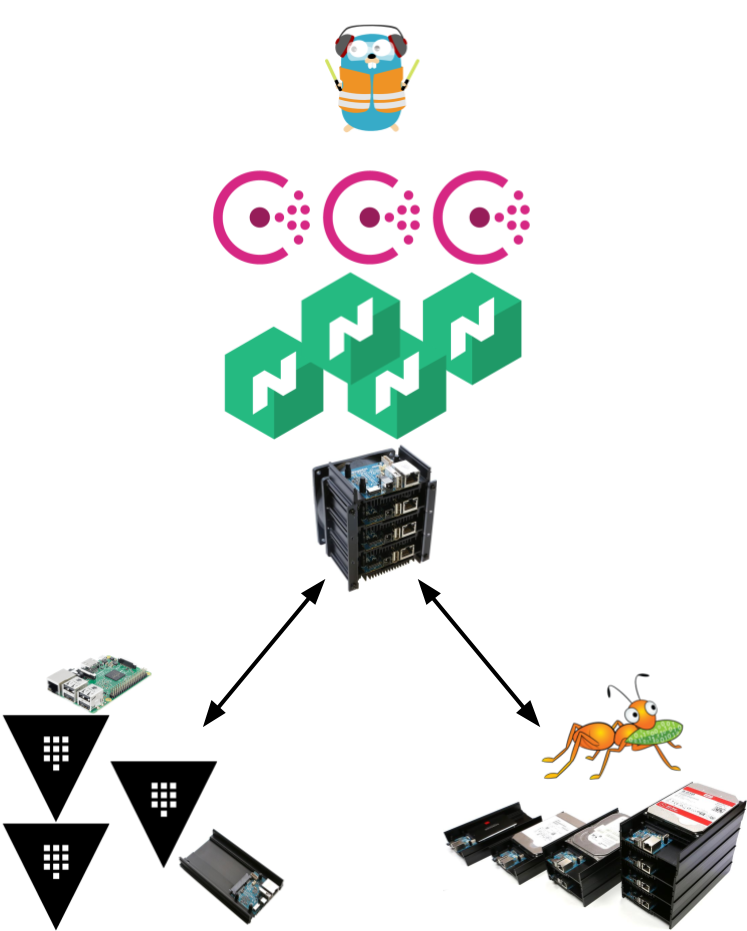
Figure 1: Do you like my homemade diagram?
I kept meaning to blog about this when I finished each piece but ended up with the novel you see before you, so while I've written up my journey in order of each system's dependencies, there's a lot to digest here - but don't let that dissuade you. It's a really fun setup - who doesn't want to config-manage a dozen machines and services in their spare time??? (probably quite a few people)
Note: Some have caught that the Gluster project has planned to drop support for 32-bit platforms. If you're planning on building something similar to what I describe in this post, tread carefully - I've already had numerous problems with GlusterFS 7.0, so test and verify your setup. Thank you to /u/legogris for catching that.
Table of Contents
Preface
Before I dig in, for any fellow SREs/DevOps folks: I wouldn't consider this a reference architecture or even a recommended approach to achieve what I've built. For example, the fact I have four hosts backing my network attached storage is probably more risky than relying on a single host's inventory of hardware when I could ostensibly fit everything I have on a RAIDZ pool with 8TB disks - Gluster is probably strictly more "correct" for a vastly larger infrastructure. Despite that fact, there's some worthwhile tidbits in here, and maybe I can steer you towards some solutions that may work elsewhere. Many aspects of what I've built actually work quite well, and would probably scale to larger deployments.
In addition, some notes here to keep in mind while reading:
- I use
example.comin place of my real personal domain I like to use for my LAN. In practice, I suggest delegating a subdomain to your LAN for things like this so that it's easy to use real domain names both inside and outside your network if necessary using some different DNS rules for resolving hosts in that domain inside and outside the network (I use thelansubdomain, personally). - I don't dive into security too much in this post. If this inspires you to build a similar stack, pay careful attention to how you're managing authorization in many of these cases (Consul access, using Vault for secrets, PKI with GlusterFS, etc.)
Part 1 - Backing Services
First, I need to cover some of the infrastructure I built to support the higher-level services I'm running in the homelab.
Persistent Storage
This piece was originally meant to be a section of its own. After many years of faithful service, my venerable HP N40L started to creak under the load of dozens of services and applications I had loaded on it.
The primary storage mechanism on that NAS is a ZFS RAIDZ, and to be clear: my perspective is that ZFS on Linux is still the king of reliable, stable storage on Linux at the moment. Scrubbing, snapshots, and send/receive have been massively useful in a very real, applicable way. However, I wanted to try a distributed filesystem this time for a few reasons:
- Experimentation, purely to try something new out (it's homelab, that's what it's for)
- When expanding my storage pool, I'd like to avoid rebuilding it. Adding a disk to a RAIDZ pool is a little inflexible, so if I can add storage incrementally as necessary, that'd be a big win
- I'd like to be able to perform maintenance (kernel updates, package upgrades, etc.) on nodes without downtime. Running a distributed filesystem means I can perform rolling restarts without losing access to my storage volume(s)
The two main contenders in this space are Ceph and GlusterFS. This article isn't about a Ceph vs. GlusterFS comparison, so here's a slimmed-down list of why I opted for GlusterFS:
- The underlying file objects are plain, recognizable files. That is, you can log in to a cluster peer, navigate to a brick for the volume you're interested in, and the files allocated to that peer aren't encoded in any special way and could potentially be recovered in a seriously bad disaster recovery scenario. Note that this doesn't hold if you're using disperse volumes (files will be erasure-encoded)
- GlusterFS is dramatically more simple than Ceph. Ceph has improved their story with ceph-deploy, which is great addition, but for a relatively straightforward environment like a small-scale personal network, I just want a POSIX-like filesystem I can mount somewhere, and GlusterFS achieves that in a couple of stock, vanilla commands
- My desired capability to expand volumes incrementally without rebuilding the storage group is possible with distributed replicated volumes
I'd note here that shortly after completing my setup, an intrepid Redditor blogged about a similar Gluster+ODroid build. If this writeup interests you, I'd recommend reading his summary as well.
Hardware
This was the fun part: when I was looking into a NAS rebuild initially, I checked out some hardware suited for a large, single-host storage machine. In a distributed storage setup, I could instead buy lots of little hosts to bind together cheap storage and cheap hosts so that expansion is affordable and hardware failure isn't a big deal.

Figure 2: Close-up of the ODroid HC2
Let me introduce you to the ODroid HC2. The hardware is purpose-built for low-cost storage clustering: the entire machine is one big heatsink and essentially just a way to make a spinning disk available over a network (the aluminum case is also stackable, so they cluster easily physically as well). In essence the board is a modified ODroid XU4, so you need to run the machine with a Linux distribution built for the armv7 architecture.
Over the course of the months I've used these boards, they've been very reliable - their NICs are performant, no crashes, and they pack more than enough power to drive Gluster with the specs of the XU4 (in fact, they're so powerful I run fully-loaded Elasticsearch data nodes alongside Gluster without any problems, but that's another blog post).
Installation
I built a 4-node cluster on Arch Linux ARM. I use Arch since I'm most familiar with it and know how to package for it easily, but in this and other ARM SBC cases, I think Armbian is a great choice as well.
I mentioned simplicity with Gluster, and this is how to peer each node.
This is what I ran from my codex01 host, and used similar commands from the other nodes in the storage cluster.
gluster peer probe codex{02..03}
Then you can check the clustered state:
shellgluster peer status
Before creating any volumes, mount your SATA-connected drive somewhere that you can consume in a Gluster brick.
Configuration
So here's some experience that bears repeating with GlusterFS: although disperse volumes are a slightly more sophisticated method of pooling storage resources, they have problems. The aforementioned other Reddit user confirmed similar problems I observed with disperse volume behavior. Despite reporting this bug upstream, it was closed as apparently the Gluster policy is to aggressively close bugs in the event of new releases, so I'm mildly concerned about the sustainability and stability of the Gluster ecosystem in general.
Despite my bad experience with disperse volumes, distributed replicated volumes have been a better experience. I went with a 2+1 setup, so I can expand my storage nodes in increments of 2 (plus one arbiter). My arbiters are other random ARM SBCs I have on my LAN that serve miscellaneous purposes but aren't pure storage nodes, if you don't have that luxury you can always go with a different distributed replicated topology with more storage nodes.
Again, using Gluster for its simplicity pays off here:
shellgluster volume create <volume-name> replica 3 arbiter 1 \brick01:/srv/storage/<volume-brick> \brick02:/srv/storage/<volume-brick> \arbiter01:/srv/storage/<volume-brick> \brick03:/srv/storage/<volume-brick> \brick04:/srv/storage/<volume-brick> \arbiter02:/srv/storage/<volume-brick>
This allocates the actual storage onto the brick nodes and purely cluster-consensus metadata to the arbiter nodes.
In this example cluster, brick01 and brick03 can become unavailable with no downtime, but brick01 and brick02 simultaneous faults will cause the files in their charge to disappear.
This means that I sort of have tolerance for 50% failure, but from what I've seen, you don't want to gamble with disperse volumes - it's an even worse experience.
The other step you should take in this setup is to enable bitrot scrubbing, which will help keep the volume healthy for you (this is enabled on a per-volume basis):
shellgluster volume bitrot <volume-name> enablegluster volume status <volume-name>
That last command returns some important information you should keep an eye on like the status of the auto self-heal daemon, which will ensure that your files are in a consistent, healthy state.
So! At this point, I've got a network volume I can mount on multiple hosts, backed by multiple machines with a degree of fault tolerance. Distributed and replicated persistent storage in the homelab: check.
Compute Hardware
As I mentioned, a collection of ODroid HC2s are running my Gluster storage cluster. What about the compute nodes that'll run the compute-heavy Nomad workloads?
Whereas the HC2 is designed as a mass storage node, the ODroid MC1 is the compute counterpart: with just an SD slot to drive the OS and no SATA interface, it isn't built to house gobs of data, but is moreso a compact compute cluster. A built-in fan fastened to the aluminum housing means that you can drive the boards relatively intensely, and like the HC2, they're completely headless (no HDMI ports here, though you can use a USB serial cable to check the hardware console).
There actually isn't much to say here: install your ARM distro of choice onto an SD card, repeat for each node, and load it up. At that point you're ready for the next steps for each compute node (Consul, Nomad, and so on). Some additional packages are necessary to support executing the workloads as well, like Docker, and you'll need your distribution's Gluster package to mount volumes that your workloads might need.
One item of note is that, if you're like me, you like to keep the metrics for your machines highly visible, and that means pulling in system stats for collection and monitoring.
The systems I experimented with (ganglia, Telegraf, a few others) get most of the story, but my MC1 nodes expose some additional data for CPU temperatures under /sys, so I use the following script as an exec input to Telegraf to watch each CPU core's temperature under load.
- Font used to highlight builtins.
- Font used to highlight strings.
- Font used to highlight variable names.
- Font used to highlight keywords.
- Font used to highlight comments.
#!/usr/bin/env shfor thermal_zone in /sys/class/thermal/thermal_zone*docpu_id=${thermal_zone##*thermal_zone}temp="$(echo $(cat $thermal_zone/temp)/1000 | bc -l | xargs printf '%.2f\n')"echo "cpu_temperature,cpu=cpu${cpu_id} celsius=${temp}"done
I use these metrics as part of a greater overall monitoring strategy with Telegraf, Prometheus, and Grafana. Metrics like this that are directly impacted by load are useful to help tune Nomad allocation resources later on when you need to gauge exactly how much CPU and memory to carve out for an application container.
Network Consensus and Service Discovery
In order to operate a system that can dynamically scale and run workloads on arbitrary hosts, you're gonna need both a) a way to discover and hit those services, and b) almost certainly some sort of consensus algorithm in the mix. My day job has healthy dose of Kubernetes, which achieves this with a) Kubernetes' service abstraction, and b) etcd. Because I wanted to build my setup atop Nomad, Consul seemed like an ideal choice for this, as it handles both and fits very closely with Nomad.
If you haven't tinkered with Consul lately, the landscape has become very operator-friendly. My distro of choice, Arch Linux ARM, ships an ARMv7 package, and setup isn't bad. If you go for a typical three-server setup for quorum and deploy clients everywhere else, it's a pretty resilient topology, which is what I did.
For the sake of completeness, here's my consul server configuration json for an example host (i.e., the host that isn't farnsworth or curie):
JSON- Font used to highlight constants and labels.
- Font used to highlight strings.
- Font used to highlight keywords.
{"advertise_addr": "{{ GetInterfaceIP }} \"eth0\"","bind_addr": "0.0.0.0","bootstrap_expect": 3,"client_addr": "127.0.0.1 {{ GetInterfaceIP }} \"docker0\"","data_dir": "/var/lib/consul","datacenter": "lan","disable_update_check": true,"log_level": "INFO","retry_join": ["farnsworth","curie"],"server": true,"ui": true}
First of all, serious love to Hashicorp for supporting golang template interpolation to dynamically set IP address, it's a really wonderful idea.
Second, note that I'm telling the client to listen on both localhost and the docker0 interface.
This is crucial, because when I end up running services in Docker containers, I need to have a way to hook those containers into the local consul daemon (and I don't feel like running consul in a container).
This permits me to instruct containers to talk to their host's IP to get at consul, which is pretty important later on.
Lastly, because consul is listening on whatever-the-ip-is for docker0, it's now dependent on the docker service being up so that interface is available to listen on, so I ended up dropping a systemd service override in for consul:
- Font used to highlight keywords.
- Font used to highlight type and class names.
- Font used to highlight comments.
- Font used to highlight comment delimiters.
# /etc/systemd/system/consul.service.d/depend-docker.conf[Unit]After=docker.serviceRequires=docker.service
After a quick
shellsudo systemctl enable --now dockersudo systemctl enable --now consul
On the consul servers/leaders, I've got a nice cluster goin'. The clients don't need quite as much in their configs:
JSON- Font used to highlight constants and labels.
- Font used to highlight strings.
- Font used to highlight keywords.
{"data_dir": "/var/lib/consul","datacenter": "lan","disable_update_check": true,"log_level": "INFO","retry_join": ["farnsworth","curie","planck"],"server": false}
That's enough to get the LAN clustered. While it isn't flashy now, consul will be critical later. At the very least, you've got some rudimentary uptime checks when you look at live cluster members:
shellconsul members
With consul operational, I took one additional step to make checking in on services that register with consul even easier from non-cluster machines (like my laptop or phone) a little easier.
The following line in my router's /etc/dnsmasq.conf instructs it to forward requests for consul domains to the local consul listener:
- Font used to highlight comments.
- Font used to highlight variable names.
server=/consul/127.0.0.1#8600
This means that, for example, I can curl nomad.service.consul:4646 from anywhere on my network to check in on Nomad, and makes some other operations easier as well that I'll go into later on.
Secret Management
Although you don't strictly need this, if you run Nomad workloads with credentials of any sort (such as database connection credentials, API keys, etc), this will enable you to avoid committing credentials when you manage Nomad tasks.
In addition, big chunks of infra like to use certs for authentication (Gluster, for example), and trust me: you will want to use Vault for PKI management and not horrendous openssl commands.
I've done this for journald-remote authentication and it works swimmingly.
For self-managed secret management, Vault is pretty much the gold standard. Good news: with consul up, you can pop Vault atop it to serve as both the high-availability and storage backend. Truly, we live in the future.
I actually opt to run Vault in a Docker container, primarily because with Consul as the state backend, I have literally no persistence and/or confguration requirements for Vault other than "talk to consul", so running as a container is just a little easier than managing an operating system package.
If you're really curious, here's the Ansible stanza for my Vault config:
YAML- Font used to highlight constants and labels.
- Font used to highlight strings.
- Font used to highlight variable names.
- name: Run Vaultdocker_container:name: vaultcapabilities:- IPC_LOCKcommand:- serverenv:VAULT_LOCAL_CONFIG: |{"backend": {"consul": {"address": "172.17.0.1:8500","service_tags": "traefik.enable=true"}},"default_lease_ttl": "168h","listener": {"tcp": {"address": "0.0.0.0:8200","tls_disable": true}},"max_lease_ttl": "720h","ui": true}image: vault:0.10.3published_ports:- 8200:8200- 8201:8201restart_policy: alwaysstate: started
I know, it needs real TLS. That's in the works; we're securing stuff like my Postgres password here, not nuclear launch codes.
Once those containers are in place, they'll cluster and you can follow the typical Vault bootstrapping steps (initializing Vault, generating unseal keys, delegating to a non-root token, and so on). That Traefik tag is for later; it'll expose Vault over TLS for us when the time comes for everyday use.
Again, I've had nothing but good experiences running this on ARM single-board computers, and Hashicorp's official images include builds for ARM, which is a rare treat. My cluster is spread among an ODroid HC1, a Raspberry Pi B+, and an ODroid XU4 on different network paths for good measure.
Part 2 - The Runtime
Okay, at this point we have reliable persistence for workloads, service discovery and distributed consensus, as well as secret management. Let's talk about actually running services and applications!
The Scheduler
It's no secret that Kubernetes is massively popular, and it's mostly deserved – it's extremely powerful, and can handle pretty much anything you throw at it. But that power comes at a cost, and you pay for it with the inherent complexity with everything it can do. I've set up Kubernetes from scratch and wow, there are a lot of moving parts, and many of those pieces are still somewhat of a mystery to me (I still don't fully grok networking between pods). I have very little confidence I could fix a problem with a broken cluster, let alone debug something occurring at the etcd consensus layer or lower.
I don't deny the irony in observing that I've had to set up many other systems to support Nomad which creates complexity anyway, but the difference is that if I experience, for example, problems with request routing in Traefik, the inputs, outputs, and configuration for that system are clearly defined and visible.
Anyway: though there are other container schedulers out there like Mesos, Rancher, and more, I thought I'd put some faith in Nomad given that I have a high degree of confidence in its component parts (Consul, Vault, and so on). It's got the typical convenient trappings of most distributed runtimes (min/max [un]available enforcement, secret injection, service advertisement, etc.) plus some that are nicer than Kubernetes (like executors other than Docker). Some features are missing - most notably for me, truly native persistent storage support and scheduling algorithms other than bin packing - but those haven't been dealbreakers.
Like most modern Hashicorp products, Nomad is a go binary, and by hooking it into Consul, we get clustering operational a little more easily. Here's a server config (Nomad also operates under the quorum of servers + rest are clients paradigm as Consul):
JSON- Font used to highlight constants and labels.
- Font used to highlight strings.
- Font used to highlight keywords.
{"bind_addr": "0.0.0.0","data_dir": "/var/lib/nomad","disable_update_check": true,"leave_on_interrupt": true,"leave_on_terminate": true,"server": {"bootstrap_expect": 3,"enabled": true},"client": {"enabled": false},"datacenter": "lan","telemetry": {"prometheus_metrics": true,"publish_allocation_metrics": true,"publish_node_metrics": true},"vault": {"address": "http://vault.service.consul:8200","create_from_role": "nomad-cluster","enabled": true}}
As you can see, I've got Nomad prepped for metrics collection via Prometheus and secret injection from Vault. My client configs are similar:
JSON- Font used to highlight constants and labels.
- Font used to highlight strings.
- Font used to highlight keywords.
{"bind_addr": "0.0.0.0","client": {"meta": [{"cluster": "compute"}]},"data_dir": "/var/lib/nomad","disable_update_check": true,"leave_on_interrupt": true,"leave_on_terminate": true,"datacenter": "lan","server": {"enabled": false},"telemetry": {"prometheus_metrics": true,"publish_allocation_metrics": true,"publish_node_metrics": true},"vault": {"address": "http://vault.service.consul:8200","create_from_role": "nomad-cluster","enabled": true}}
Metadata for scheduling tweaks is very useful - in addition to adding metadata for homogeneous nodes, I also add some node index/count data for more flexibility.
With the previously-mentioned changes to DNS resolution, I can hit a simple DNS name to run typical nomad commands from my workstation (with or without a local consul agent):
NOMAD_ADDR=http://nomad.service.consul:4646 nomad status
In addition to some lovely dashboards available at the same address:
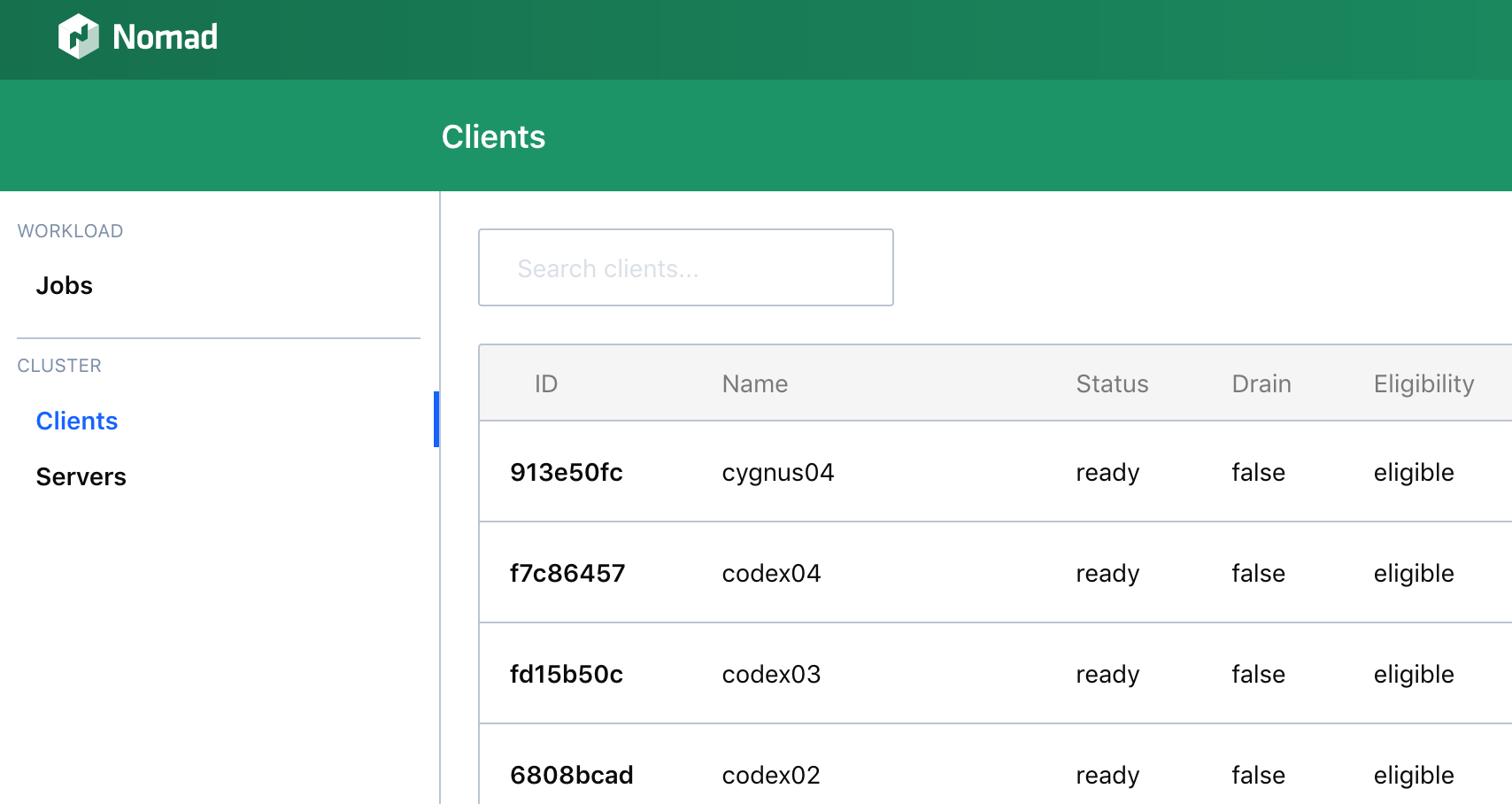
Figure 3: Nomad Web Interface
Exposing Applications
At this point we nearly have a ready-made system to submit workloads and run them in a highly-available, clustered setup. However, one more piece will make webapps infinitely more easy to use once we deploy them: Traefik.
In a nutshell, Traefik looks at the metadata for schedulers like Kubernetes, Mesos, Nomad, and others, and acts as the routing glue so that you can talk to a simple frontend like https://app.mydomain.com and Traefik will send traffic to the right workload (container), no matter where it's running - which is important when your applications can be running on any given host in a cluster at any time (potentially even multiple hosts).
For an introductory tour of Traefik, I do recommend checking out the docs to get started, since there are a lot of concepts in there to get familiar with. This post is already pretty excessive, so I'm not going to give a blow-by-blow of how it works, but rather the highlights to get it up and running.
First: the configuration backend. You can configure Traefik with a simple config file, but storing your configuration in Consul lets you 1) run more than one Traefik instance for high availability, 2) alleviate the need to manage a config file and related storage, and 3) lets you dynamically configure several aspects of Traefik just by writing Consul keys (which has been really nice in practice).
To get Traefik's configuration bootstrapped in consul, there's a helpful storeconfig command:
cat traefik.toml
loglevel = "INFO"defaultEntryPoints = ["https","http"][entryPoints][entrypoints.api]address = ":8080"[entryPoints.http]address = ":80"[entryPoints.http.redirect]entryPoint = "https"[entryPoints.https]address = ":443"[entryPoints.https.tls][consul]endpoint = "172.17.0.1:8500"watch = trueprefix = "traefik"[acme]email = "you@example.com"storage = "traefik/acme/account"entryPoint = "https"[[acme.domains]]main = "*.example.com"sans = ["example.com"][acme.dnsChallenge]provider = "route53"
traefik --consul.endpoint=127.0.0.1:8500 storeconfig traefik.toml
This (more or less) gets your Traefik config Consul-ized. Next you need to run Traefik somewhere. Sounds like a perfect fit for a clustered, dynamically scaling runtime like Nomad!
HCL- Font used to highlight constants and labels.
- Font used to highlight comments.
- Font used to highlight comment delimiters.
- Font used to highlight type and class names.
- Font used to highlight variable names.
- Font used to highlight strings.
job "traefik" {region = "global"datacenters = ["lan"]type = "service"constraint {attribute = "${meta.cluster}"operator = "=="value = "compute"}task "traefik" {driver = "docker"config {image = "traefik:1.6.5"args = ["--accesslogsfile=/dev/stdout","--web","--consul.endpoint=172.17.0.1:8500","--consulcatalog","--consulcatalog.endpoint=172.17.0.1:8500",]port_map {admin = 8080http = 80https = 443}}resources {cpu = 100 # Mhzmemory = 64 # MBnetwork {mbits = 10port "admin" {static = 8080}port "http" {static = 80}port "https" {static = 443}}}service {name = "traefik"port = "admin"tags = ["traefik.enable=true","traefik.frontend.entryPoints=http,https"]}template {change_mode = "restart"destination = "local/values.env"env = truedata = <<EOF{{ '{{' }} with secret "aws-personal/creds/ddns" }}AWS_ACCESS_KEY_ID = "{{ '{{' }} .Data.access_key }}"AWS_SECRET_ACCESS_KEY = "{{ '{{' }} .Data.secret_key }}"{{ '{{' }} end }}{{ '{{' }} with secret "secret/ddns" }}AWS_HOSTED_ZONE_ID = "{{ '{{' }} .Data.hosted_zone_id }}"{{ '{{' }} end }}EOF}vault {policies = ["ddns"]}}}
Some notes about this configuration:
- I'm using the Route53 ACME DNS provider backend coupled with Vault secrets for authentication. This gets me easy Let's Encrypt certs using purely ephemeral AWS creds that Vault creates then destroys just for this purpose.
- Traefik (thankfully) builds and serves images for ARM architectures, so no special steps are necessary to run this on my ODroid MC1 cluster.
- The constraint you see defined is necessary since I also run Nomad clients on my storage cluster. All nodes outside of my
storagecluster get pooled into mycomputecluster. I do this so that I can run some Nomad tasks on my storage machines if needed, though that's another use case that I may cover in another post.
That's it! But we're not quite done without some changes to the router on the network to make this even more easily accessible.
With this setup, the Traefik container will now happily serve domains under *.example.com.
If you have a network infrastructure which you can CNAME something like foo.example.com to traefik.service.consul, great: when your browser asks for foo.example.com, your router will reply with a CNAME to Traefik, you'll snag the right IP (wherever in the cluster it's running), and you'll get routed correctly.
In my case, my router is on dnsmasq, and unfortunately, dnsmasq can't CNAME addresses to names outside of its scope (that is, names it has assigned).
I had to get a little creative, and found a solution that isn't pretty, but is functional.
I listen on my router's LAN interface for HTTP/HTTPS and proxy all requests to Traefik by using nginx DNS lookups.
Thus a request for foo.example.com resolves to my router's IP address, and my router forwards traffic on port 80 and port 443 to whatever IP traefik.service.consul currently has.
The config was actually kind of hard to put together since reverse TCP proxying using DNS lookups is a pretty esoteric use case, but this is what it actually looks like in practice:
- Font used to highlight variable names.
- Font used to highlight keywords.
stream {resolver 127.0.0.1:8600 valid=10s;map $remote_addr $traefik {default traefik.service.consul;}server {listen 80;listen 443;proxy_pass $traefik:$server_port;}}
Note that this requires Consul on the same host to resolve DNS queries for *.consul domains - heavily firewall your router as necessary.
Also note: I used HAProxy for this initially, which works great (and, incidentally, supports discovery of hosts over SRV records while nginx only does so in their paid version), but I needed UDP proxying as well for netflow collection, so I used nginx in the end.
In this setup, you need to have some DNS records set to point your apps at your router, but that's an easy task.
Part 3 - Using It
Alright, we've got a functional container/distributed execution runtime! Time to use it.
Prelude - A Private Registry
At this point, we can start hosting applications. If you're purely pulling public images from the Docker hub for your applications and everything you need is there, great! However, in my case, there are a lot of applications that don't ship images for ARMv7 CPUs. You can build and push these to the Docker hub, but I found it easier to just host a private registry on my LAN. As an added bonus, internet availability doesn't impact your ability to run and bring apps up and down, which is pretty important to me.
Of course, you need the registry hosting software present in the first place, so there's a dependency on the Docker hub to get your private registry running. Here's what my Nomad config looks like for my self-hosted registry:
HCL- Font used to highlight type and class names.
- Font used to highlight variable names.
- Font used to highlight strings.
job "registry" {datacenters = ["lan"]region = "global"type = "service"priority = 80constraint {attribute = "${meta.cluster}"operator = "=="value = "compute"}task "registry" {driver = "docker"config {image = "budry/registry-arm"port_map {registry = 5000}volumes = ["/srv/storage/registry:/var/lib/registry"]}service {name = "registry"port = "registry"tags = ["traefik.enable=true","traefik.frontend.entryPoints=http,https"]}resources {cpu = 100memory = 64network {port "registry" { }}}}}
The config here isn't too bad, but the persistent storage is import to touch on.
The mount point /srv/storage/registry is a Gluster volume mount present on each member of the cluster.
Here's the mount snipped in fstab form:
- Font used to highlight variable names.
codex01:/registry /srv/storage/registry glusterfs defaults 0 0
With this mounted on each node that may potentially receive the registry job for scheduling, the container can always mount the data and persistence will "follow" the task since the shared storage volume is mounted everywhere.
Since we include the helpful Traefik tags to indicate we want the service exposed, I can hit the registry via a plain DNS name to see my catalog of images:
http -b https://registry.example.com/v2/_catalog
- Font used to highlight strings.
- Font used to highlight keywords.
{"repositories": ["bitwarden_rs","elasticsearch","ganglia","kibana","logstash","prometheus","tt-rss"]}
Now we can build and host Docker images locally with a highly-available, fault-tolerant, and distributed registry. Great!
Deploying Bitwarden
I tweeted a while back that I use Bitwarden now. It's a pretty nice self-hosted password manager that doesn't require your significant other to try and navigate the inscrutable maze that is GPG!
While the fact that you can host your own Bitwarden server is delightful, I am absolutely not about to deploy an application under my stewardship that requires a bunch of shell scripts to manage and stands up numerous behemoth containers with things like MS SQL server. Who would do that? You're much better served by deploying something will well-defined configurations and a simpler architecture that doesn't use a bespoke management procedure.
Fortunately, an enterprising OSS developer has released bitwardenrs, a Bitwarden API server which runs as a simple, easy-to-deploy Rust API server. It persists data to a sqlite file, and that's it - the provided Docker container even bundles the web UI. I've been using it for a while, and I can vouch for the fact that it works great.
All of the preceding infrastructure I've outlined make this really pleasant to setup.
First, we need to build an image.
If your cluster is on x86 CPUs, this isn't necessary, but bitwarden_rs doesn't ship an ARM container by default.
That said, it isn't hard to make the Dockerfile for bitwarden_rs ARM-compatible.
Here's the diff that made the Docker image buildable and runnable on an ARMv7 CPU:
- ‘diff-mode’ font used to highlight function names produced by "diff -p".
- ‘diff-mode’ font used to highlight added lines.
- ‘diff-mode’ font used to highlight removed lines.
- ‘diff-mode’ font used to highlight context and other side-information.
- ‘diff-mode’ font used to highlight hunk header lines.
- ‘diff-mode’ font used to highlight file header lines.
- ‘diff-mode’ font inherited by hunk and index header fonts.
diff --git a/Dockerfile b/Dockerfileindex 91e1d95..7a37a09 100644--- a/Dockerfile+++ b/Dockerfile@@ -2,12 +2,12 @@# https://docs.docker.com/develop/develop-images/multistage-build/# https://whitfin.io/speeding-up-rust-docker-builds/####################### VAULT BUILD IMAGE #######################-FROM node:9-alpine as vault+FROM node:9 as vaultENV VAULT_VERSION "1.27.0"ENV URL "https://github.com/bitwarden/web/archive/v${VAULT_VERSION}.tar.gz"-RUN apk add --update-cache --upgrade \+RUN apt-get update && apt-get install -yq \curl \git \tar \@@ -65,7 +65,7 @@ RUN cargo build --release######################## RUNTIME IMAGE ######################### Create a new stage with a minimal image# because we already have a binary built-FROM debian:stretch-slim+FROM rustENV ROCKET_ENV "staging"ENV ROCKET_WORKERS=10
With that, you can build and push the container image to the private registry (or your Docker Hub account):
shelldocker build -t bitwarden_rs:master .docker tag bitwarden_rs:master registry.example.com/bitwarden_rs:masterdocker push registry.example.com/bitwarden_rs:master
Now that we have an image we can use, all that's left is the Nomad config.
I mentioned previously that bitwarden_rs persists data to a SQLite file, so this is another candidate for our shared storage mount across cluster nodes.
Aside from that, we'll be using the web app, so exposing a TLS-secured endpoint over Traefik will be important as well, so I include those tags in the Nomad service stanza.
- Font used to highlight type and class names.
- Font used to highlight variable names.
- Font used to highlight strings.
job "bitwarden" {datacenters = ["lan"]region = "global"type = "service"constraint {attribute = "${meta.cluster}"operator = "=="value = "compute"}task "bitwarden" {driver = "docker"config {image = "registry.example.com/bitwarden_rs:master"port_map {http = 80}volumes = ["/srv/storage/apps/bitwarden:/data"]}env {DOMAIN = "https://bitwarden.example.com"}service {name = "bitwarden"port = "http"tags = ["traefik.enable=true","traefik.frontend.entryPoints=http,https"]}resources {cpu = 200memory = 64network {port "http" { }}}}}
That's about it.
The DOMAIN environment variable is specific to bitwarden_rs to enable FIDO 2FA with the application.

Figure 4: Bitwarden
Summary
After using a Docker registry and Bitwarden as an example, I hope they illustrate how awesome this setup is for deploying and running applications:
- The runtime artifact is just a Docker image, and building/hosting those custom images is stupid easy. What's more, since your registry is backed by a GlusterFS cluster, I can expand the registry storage arbitrarily by adding nodes on the backend as necessary.
- Traefik makes routing traffic to these containers - over TLS - almost effortless. It doesn't matter where the applications run (because my ODroid MC1 cluster has four nodes), Traefik will dynamically discover where the services run and balance requests between them.
- I can show you almost the verbatim Nomad configs because my secrets get pulled in via Vault, so credentials like Route53 keys are totally handled by Vault for workloads that need them.
In the end, I've deployed maybe about a dozen services so far on my little ARM compute cluster. If there's any interest (leave a comment, send an email, etc.) I can go into more detail, but here's a sampling of what I'm hosting now:
- Prometheus to collect metrics for everything - it sits atop a Gluster mount for storage, and works great with a small resource footprint. I used to use ganglia religiously, but I hit arcane error messages when I started using ganglia in my (admittedly edge-case-ish) scenarios on ARM boards and over Gluster network mounts.
- Tiny Tiny RSS and a sibling Postgres deployment. This was fun to setup since I point tt-rss at the dynamic
postgres.service.consulname on my network, and Consul acts as the service mesh glue to associate separate workloads on my Nomad cluster. I actually tried to implement the Vault Postgres secret backend to dynamically generate Postgres credentials on-the-fly for tt-rss, but I need to work on that a bit more. Once that's done, tt-rss will use purely ephemeral credentials to connect to my database, and I won't need to store connection credentials anywhere at all. - Logstash. Calling back to my router post and how I collect netflow data, I wanted to run Logstash on my cluster and used a similar approach to my router nginx reverse TCP proxy setup in order to send netflow data to my router's loopback address, then proxy that UDP stream out wherever
logstash.service.consulis. - Elasticsearch. Yes, it's actually performant enough on ARMv7 to be a useful analytics tool. This is (another) blog post that needs to be written, but running Elasticsearch on ARM boards is non-trivial and takes some work to get reasonably performant. The tl;dr secret is to use a JVM that has native ARMv7 support - if you use, for example, a vanilla OpenJDK 8 build on Arch Linux ARM, performance will be so bad it's nigh-unusable. The eminently professional @shipilev set me straight on Twitter despite my snarky tweet, and he provided some great links to ARMv7 OpenJDK 10 builds that work fantastic with the latest ODroid boards.
Synopsis and Future Work
That's a (somewhat) high-level overview of how I've refactored my homelab from a very overloaded single server into a distributed, fault-tolerant, cheap-to-operate Nomad cluster based on ARMv7 boards (plus supporting services like Gluster and Vault). I think it's an improvement over what I had previously. Is it more complex? Sure. But when I (inevitably) hit capacity in the future - whether in compute power or storage space - expanding my homelab is almost trivially easy: add more ODroid HC2 bricks for space, or join a couple more nodes to my Nomad cluster when I need more horsepower.
This wouldn't be educational without some "lessons learned", so:
- Don't try any ops projects with
nservers without using configuration management for values ofngreater than 1, seriously. I hand-managed my HP N40L, but after writing some very simple ansible this got a lot easier. As a sub-point, I would suggest not using config management roles you find online - just write them yourself, custom roles end up being very simple when you're not trying to support every distro version under the sun. - Run some disaster recover scenarios. My problems with Gluster disperse volumes would have been a huge pain if I hadn't pulled a few ethernet plugs to observe failure modes before putting my data on it. Contrast this with Nomad, which handled failures so well that last week one of my MC1 nodes died and I literally couldn't tell it happened for several hours because each failover piece - Nomad, Consul, Traefik, etc. - handled the member loss gracefully (loose network cable, if you were interested).
- Modern software still isn't "optimize for concurrency" instead of "optimize for clock speed." ODroid XU4s have mostly-okay core clocks speeds, but they do pack eight cores into each board. Despite this degree of parallelism, many of the applications I've experimented with can struggle because they expect a fast CPU core and don't spread among multiple very well. In practice this hasn't limited me from running anything yet, and the ODroids do surprisingly well - but do not expect modern x8664 clock speeds (though you will save a ton on electricity).
In terms of other interesting things I'm doing with my homelab, there are other projects in the works that may be of interest that are slated for more writeups in the future:
- My monitoring story is a combination of Telegraf + Consul + Prometheus service discovery through creative use of Consul's catalog feature. It means I can monitor hosts dynamically when they register in Consul so I don't explicitly configure them for monitoring, an it works great.
- One huge reason for using ARM single-board computers - lower power consumption - is something I haven't benchmarked rigorously yet. Although anectodal power measurements certainly imply it's hella cheaper than a big x8664 rig, I have more plans to measure this more rigorously via my UPS and Prometheus.