You can build your own voice assistant to avoid the questionable privacy consequences of bringing an Alexa or Google Assistant into your home. In this post I’ll explain how I did it using commodity hardware without any need for network communication outside of my own private LAN. Even more stunning, the voice recognition doesn’t suck and it may actually be useful to you.

Figure 1: AIY Voice Kit Hardware. Yes, it’s cardboard! It’s a feature!
Caveats: I built my solution a few years ago, so the DIY state-of-the-art may be different now. However, my setup continues to work well to the extent that I have no need to upgrade or replace it, so it may be a good choice for you as well. Additionally, this post isn’t meant to be a lengthy diatribe about the virtues about local-first services or privacy awareness. I’m paranoid about it, which I think is justified, but if this approach feels like too much work in lieu of just buying an Alexa device, then that’s fine. I’ll never buy one, though, so my hope is that this proves useful for people who want the same functionality in a more privacy-respecting package like I do.
The summary will give you the short notes if you want a more self-directed guide, but it’s still useful as an outline once you continue onto introduction.
Table of Contents
Summary
Okay! For those who are more self-directed and adventurous, here’s the bill of materials and related software you’ll need to purchase and install, respectively:
Hardware
- Google AIY Voice Kit v1
- The v1 part is important. v2 is based on a Pi Zero, which is supposed to pack sufficient punch, but in my experience, the Pi Zero has a significant and noticeable delay while recognizing wake words due to its more limited horsepower.
- Typically, you can’t find the v1 kit from retailers or online stores - I’ve bought more than one kit over eBay, so I’d recommend that approach.
- I understand you may see some irony with my bellyaching about privacy concerns while using Google hardware, but we’ll use other software - we just want the hardware.

Figure 2: Raspberry Pi
- Raspberry Pi 3
- Honestly: you may have a hard time with this one. Pi SBCs are so hard to find right now, and for this build, you must use an AIY v1 compatible board, which is the 3 series, and ideally one of the later revisions for improved stability and performance (like the 3B+). If there aren’t any on pilocator, eBay may once again be your best option.
- Pi accessories: power cord & SD card
- Remember to buy a power supply that can drive the hardware without stability concerns. This means a 5V supply with 2.5A – I’d suggest buying a Cana Kit power supply; they’re designed for this an often have inline power switches as well.
- If you don’t have an SD card handy, use the support matrix from the Embedded Linux wiki to find one for the operating system image (or, again, just get a Pi-less Cana Kit).
- A moderately powerful base station for Rhasspy
- Rhasspy operates by leveraging the Pi as the ears and mouth for voice recognition but offloading the difficult parts onto more powerful hardware. There may be more optimized voice recognition models that can work on a self-contained Pi, but I haven’t found any.
- If you don’t have a homelab or continuously-running server yet, then now’s your chance! If you don’t want to do this, your latency delay will probably be frustrating. The Pi lacks the horsepower to recognize commands and respond quickly enough.
- It’s expensive, but the ODroid H3 is small enough that it doesn’t require a ton of space and the prior model (the H2+) works well as my Rhasspy base, so the H3 should have plenty of CPU power. If that’s not an option, I’d bet that a typical unused consumer-grade laptop can handle it.
Software
- A Raspberry Pi Linux distribution
- You can make this work with Raspbian, Armbian, or Arch Linux ARM (which I use because I’ve standardized most of my lab on Arch Linux)
- An installation of MQTT on your network
- I use mosquitto, you can do the same and just run it on your base station if you’d like. The H3 can run this in the background without any noticeable resource impact.
- When you configure Rhasspy, it’ll need MQTT connection information, so you probably want to set this up before you head on to getting Rhasspy installed.
- Rhasspy on the base station
- The instructions are useful here (I run mine in Docker containers) – use the instructions for a multi-machine “satellite and base station” topology.
- Rhasspy on the Pi
- Again, I run mine in Docker and it works well. Same instructions, but for the satellite this time.
- Software to take action on the recognized voice
Intents. There are some higher-level services that can do this, but I wrote a small Python daemon that runs as a service in my lab. If you don’t want to write your own software, integrating with Home Assistant or Node-RED is probably simplest.
Want more step-by-step instructions? Carry on, soldier.
Introduction
I’d been trying to build the system you’ll read about here a few times over the past several years, but there are some consistently difficult problems to overcome in order to make it work well.
The hardest challenge is that voice recognition is slow – if not impossible – to perform on the Pi alone. You can run some lower-accuracy models on the Pi like Sphinx, but many of them are so inaccurate that they render the entire speech-to-text process worthless anyway (there’s no point in running a voice assistant if you can never get it to recognize anything). I originally used Jasper but never had success with it. I iterated on this problem over the years but never found anything that was accurate enough and quick enough.
Note: Whisper seems to have a lot of promise for on-device voice recognition, but the other pieces of the voice recognition ecosystem seem to still be catching up.
Note that, if you want good voice recognition and don’t mind relying on a third party, some options may exist that fit your requirements. Some, like Mycroft, even purport to be more privacy-focused, which is laudable. However, I’m explicitly looking for something completely local and custom, so I still needed alternatives (privacy and reliability are my chief concerns).
The solution I’ll explain at length – Rhasspy, AIY, and Python – works pretty well. It can recognize pretty much any command my wife or I throw at it, and I’ve integrated it into the following systems:
- It controls our music played via mopidy over MPD
- We control our blinds with soma-ctrl
- Media playback by integrating with Kodi’s API
- I wrote a bit of Python to act as a kitchen timer (create, delete, list, and sound off on completed timers)
- Turn our TV on and off
- Some simple informational functions (tell the time, outside temperature, battery levels for household devices, etc.)
- Adding items to our shared Anylist. Hey Anylist, make an official API! Please!
Here’s a copy/paste from my voice assistant code, if you’re curious:
Python- Font used to highlight strings.
- Font used to highlight variable names.
known_intents = [
"GetTime",
"GetTimer",
"GetTemperature",
"GetGarageState",
"CancelTimer",
"ControlMusicPlayback",
"ControlMusicVolume",
"ControlMusicPlaylist",
"ControlMusicMode",
"DaySummary",
"Interrogate",
"MusicLoadAlbum",
"MusicLoadPlaylist",
"MusicGetPlaying",
"Thermostat",
"KodiPlayTV",
"KodiPlayEpisode",
"KodiPlayMovie",
"KodiStop",
"KodiVolume",
"ShadeBattery",
"ShadeControl",
"ShoppingList",
"TimerStart",
"TVControl",
"Undo"
]
Undo is a wild one. I store my recorded commands in a stack and can pop them off the stack in order to undo previous commands. But that’s a post for another time.
Bear in mind that, if you follow my guide, the solution isn’t free – all of this takes hardware, and the do-it-yourself voice assistant landscape isn’t foolproof. But I’m happy with what I have!
Guide
This isn’t a trivial process, but it is doable. Please refer to [summary](#summary) for an outline. We’ll begin with hardware – what you need to buy and have on-hand before continuing with the software side.
Hardware
There are a few key components for this particular setup:
Audio Recording/Playback
The Google AIY project is a collection of hardware components that you can buy for the Raspberry Pi family of SBCs intended to teach AI/ML libraries with a focus on Google services. However, you don’t actually need to hook into any Google services to use the hardware! It turns out that it’s fully compatible with pretty much any modern Pi OS and we can just repurpose the hardware for our own intentions.

Figure 3: AIY Voice Kit Packaging
The v1 is a slightly larger model (physically speaking) that accepts a Raspberry Pi 3 as the supporting SBC for a microphone and speaker assembly. The v2 model is the current-gen version that runs on a Pi Zero. I have tried both v1 and v2, and at least for on-board processing requirements, the Pi Zero really struggles. My Pi Zero-based voice assistant has noticeable and sometimes unusable latency when responding to wake words, so I don’t recommend it. The v1 kit is a little dated, but the Pi 3 is more than adequate to run Rhasspy without issue. So use that!
While you could feasibly cobble together your own hardware for audio recording and playback with general parts, I opted to yoink this hardware because it’s:
- affordable - the assembled enclosure is cardboard(!) which is great for the first pass at this project and could easily level up into something more sturdy, like a 3d printed case. Affordability also means “easily replaceable” if something ever goes really wrong.
- guaranteed compatible with well-supported SBC hardware (the Pi). You don’t need to worry about weird out-of-tree kernel drivers, the AIY hardware is made for the Pi 3 and Pi Zero.
- already designed as a voice assistant. It’s compact, has a good microphone and speaker for interacting via audio, and has lots of useful extras (onboard wifi, bluetooth)
Because the Pi 3 (and Pis in general) are almost impossible to purchase anywhere and the v1 AIY kit has been superseded by v2, your best bet to acquire this hardware is eBay. Go forth and purchase, just be sure that you’re getting the v1 AIY and not v2. Additionally, get a compatible SD card for the OS on the Pi 3 and a power supply that pushes 2.5A (the power supplies that Cana Kit sells are nearly always a safe bet). A 2A supply may not be able to adequately drive the SBC as well as the AIY microphone and speaker hat.
Base Station
While the Pi 3 functions as a speaker, microphone, and wake-word listener, it lacks sufficient juice to run the really heavy-duty voice recognition algorithms that are necessary to achieve usable levels of success when parsing out human speech. Rhasspy cleverly offloads this task across the network via the MQTT bridge between your voice assistant “satellite” and the “base” that runs elsewhere, crunching the audio waveforms to turn them into programmatic symbols.
You’ll need something more powerful than a Pi 3 that can chat over an MQTT connection to serve in this function for the system. If you’re a fellow homelabber, there’s a good chance that your hardware can do this – it requires some horsepower, but nowhere near massive levels of it.
I can’t answer whether individual CPUs can handle the requirements, but what I can say is that my home base for Rhasspy is an ODroid H2 (that links to the ODroid H3, which is the in-stock successor to the H2). Note that the appearance of “droid” everywhere doesn’t mean this is Android hardware, the H3 is a fully-featured (albeit very physically small) x86-64 machine. If you spring for something like the H3, it has sufficient power to run everything you need: it can run an MQTT server that Rhasspy needs as well as any potential automation you may write to respond to voice assistant commands (mine is a small Python daemon). ameriDroid is a good ODroid supplier if you’re inclined to get one.
Setup
The base station should be setup as any old Linux server. You’ll probably want to run the Rhasspy base as a Docker container, so as long as the distribution you choose can run containers and Linux services, that’s good enough.
The Pi 3 can be setup with the AIY voice kit per the instructions, but stop once you reach the software instructions that start writing proof-of-concept code to interact with the speaker and microphone.
Rhasspy can just talk to the hardware once the system has configured it correctly – if I recall, I think the AIY instructions assume Raspbian as the base operating system, but the AIY hardware is actually a .dtb you can load from any distribution.
Here’s what it looks like to enable the hardware in Arch Linux ARM (add the line to /boot/config.txt and reboot):
grep voice /boot/config.txt
dtoverlay=googlevoicehat-soundcard
Your Pi 3 should be able to play and record audio. Onward!
Software
Rhasspy makes this project possible by using the speaker/microphone site to act as a simple listener (to key off wake words and stream recorded voice to the base station) and text-to-speech device (because the base can write audio to the common MQTT channel that the Pi listens to). I understand that there are other systems out there like S.E.P.I.A. that work similarly, but I haven’t tried them. First, install the prerequisite services, then go for Rhasspy:
MQTT
I’d suggest setting this up first. MQTT serves as the communication layer between Rhasspy satellites – the Pi’s with AIY hats attached – and the base station.
Setting up MQTT is outside the scope of… well, honestly, I just don’t want to write it all out. Just search around for how to install and run mosquitto, which is a very simple and easy-to-run implementation of MQTT. Once you’re done setting it up, you should have a reachable DNS/hostname endpoint to reach it from your Rhasspy satellite and base station, ideally with an accompanying username, password, and trusted TLS CA information.
Rhasspy
Rhasspy must be installed on both the Pi listener endpoint as well as the base station. At this point I’d recommend just relying on the [Rhasspy documentation][rhasspy] to get going. In particular, you should reference the guide for “Server with Satellites” in order to get the right architecture with your Pi and base station. Here’s some key points to remember:
- MQTT is critical to this setup. Both the satellite and the base station need it in order to pass messages back and forth.
- Pay close attention to the services that are running on the satellite and base. The satellite has specific functions that the base doesn’t and vice versa.
The Rhasspy docs are very good. You’ll finish at the point where you have messages actively being parsed out and broadcast on MQTT. Very exciting!
Using It
Now you’ve got commands being recognized and published across MQTT. How do you actually use this?
If you intend on hooking into this setup with pre-built integrations like Home Assistant or Node-RED, then just use the Rhasspy docs. You may already be done at this point if that’s all you need!
For maximum flexibility, though, you can write a little Python for complete control. Fortunately, the protocol that Rhasspy uses (Hermes) is very pleasant to use. You simply instruct Python to listen on an MQTT topic and receive JSON with your commands – at that point, you can do whatever you want!
I’ll include some runnable code, but the basic setup looks like this:
- Subscribe to the right MQTT topic
- Consume messages and parse them out as JSON
- Handle them any way you like and optionally send text to speak back out over MQTT
The first step is configuring Rhasspy via the web interface – it listens on port 12101. Navigating to the Sentences page will let you create Intents which, upon detection, will get broadcast onto MQTT.
The Python I’ll share responds to the GetTime intent, which you can configure like this:
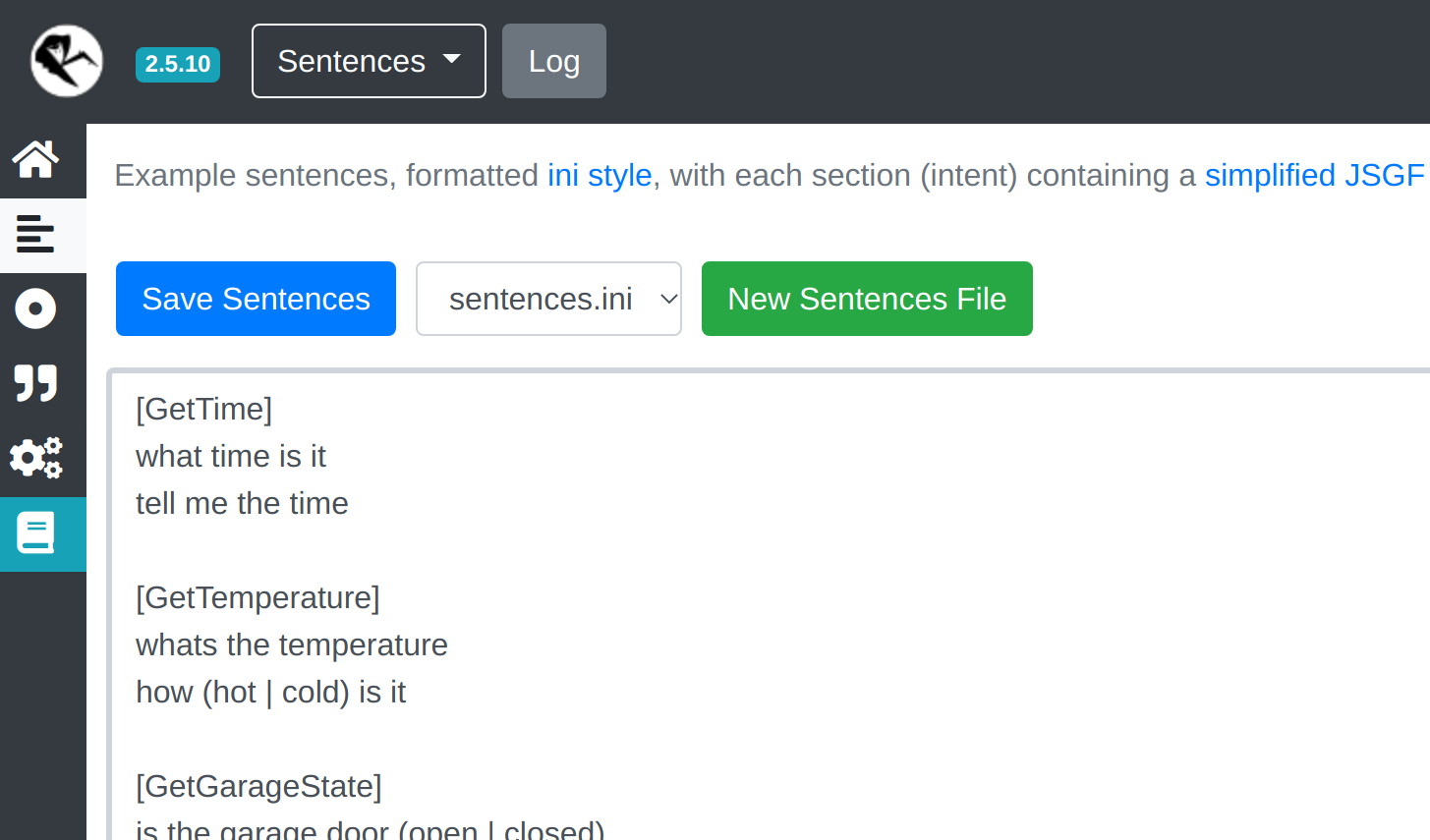
Figure 4: Rhasspy Sentence interface
This is a key concept about how Rhasspy works: you predefine all the commands that it should recognize, and Rhasspy will train itself on the given words so that once it starts listening it’ll be as accurate as possible. You can technically make free-form input work if you’d like, but the default pre-training scheme works well. Remember that intent recognition occurs on the base station in this setup, so you’ll define sentences on base-station-hostname:12101.
The coupling point between Rhasspy and your automation is each intent – the token between the brackets on the Sentences page.
Take a look at the following code, which assumes Python 3.10 (for pattern matching) and that you’ve installed asyncio-mqtt as a Python library dependency:
- Font used to highlight constants and labels.
- Font used to highlight comments.
- Font used to highlight builtins.
- Font used to highlight numbers.
- Font used to highlight strings.
- Font used to highlight property references. For example, property lookup of fields in a struct.
- Font used to highlight function calls.
- Font used to highlight variable names.
- Font used to highlight documentation embedded in program code. It is typically used for special documentation comments or strings.
- Font used to highlight type and class names.
- Font used to highlight operators.
- Font used to highlight function names.
- Font used to highlight variable references.
- Font used to highlight keywords.
import asyncio
import json
from asyncio_mqtt import Client
from datetime import datetime
from typing import Optional
def get_time() -> str:
'''Return the current time interpolated into a human-readable
sentence.
'''
now = datetime.now()
if now.minute == 0:
r = now.strftime("%I")
elif (now.minute // 10) > 0:
r = now.strftime("%I %M")
else:
r = now.strftime("%I o %M")
return f"It is {r.removeprefix('0')} " + ' '.join(list(now.strftime("%p")))
async def handle(payload: dict) -> Optional[str]:
'''Accept a Hermes payload and handle the Intent. Note that
whenever you reconfigure Rhasspy to recognize new Intents, you'll
need to add a branch here that knows what to do with it.
'''
match payload['intent']['intentName']:
case 'GetTime':
return get_time()
case _:
return 'Unrecognized command'
async def run():
'''Program entrypoint. Connect to MQTT, subscribe to some chosen
topics, and handle incoming Hermes payloads.
'''
async with Client('mqtt.network.name', username='myuser', password='mypass') as client:
# Successful intent recognition arrives on this topic
await client.subscribe("hermes/intent/#")
# Unknown commands arrive on this channel if you’d like to
# handle them.
await client.subscribe("hermes/nlu/intentNotRecognized")
print("Connected. Waiting for intents.")
async with client.unfiltered_messages() as messages:
async for message in messages:
nlu_payload = json.loads(message.payload.decode())
print(nlu_payload)
response = None
match message.topic.split('/'):
case ['hermes','nlu','intentNotRecognized']:
response = "Unrecognized command!"
print("Recognition failure")
case ['hermes','intent', _]:
print("Got intent:", nlu_payload["intent"]["intentName"])
response = await handle(nlu_payload)
# Optionally, if handle() returns a string, assume
# it’s in reply to the Intent and hand it back to the
# same site in the right Hermes payload.
if response:
print(response)
await client.publish(
"hermes/tts/say",
json.dumps({"text": response, "siteId": nlu_payload["siteId"]}))
if __name__ == '__main__':
asyncio.run(run())
You’ll probably want to borrow my run() function which is where the nuts and bolts are and remember to change the mqtt connection parameters. It illustrates how to communicate over MQTT both in a receiving direction (when Rhasspy places a recognized Intent onto the topic) as well as sending (in order to initiate spoken text at a given site to respond to a question, for example).
This code uses asyncio as well, because some of my intent handlers are async, so it was just easier to make everything async from the top down.
As you might imagine, this approach essentially lets you do whatever you want in response to incoming intents from Rhasspy.
This “tell me the time” example is simple, but you could feasibly make HTTP calls with the requests library (which I do in my full Python handler) or anything else with normal Python.
My aforementioned list of known_intents may be useful to spark ideas.
Packaging and/or running your Python listener is left as an exercise to the reader.
I run all my applications in my homelab via Nomad, but you could easily contain the entire automation code in a single python file and run it in a simple python voiceassistant.py kind of way (assuming you install the right MQTT dependencies). Or put it in a Docker image. Your choice! I’m not the boss of you!
Conclusion
This setup has worked well enough for me that I’ve built three devices total: my first AIY v1, then an attempt with a v2 kit and, after finding that v1 is better than v2 for this use case, another v2 in a second room in our home. An added benefit of the Rhasspy satellite/base strategy is that expanding your voice assistant footprint only incurs the effort for additional satellites – you just re-use your base for each one, which hooks into all of your existing intents and slots. Very convenient.
If you have any questions, I’m happy to answer!