Remember when we all used to commit secrets to source code repositories? In the bygone software engineering paleolithic era, public cloud key management services didn’t exist and neither did OSS solutions like Vault. Managing sensitive credentials has gotten much better over the years, and there’s very little reason to ever even store passwords or tokens in plaintext files any more.
Somewhere in-between the Big, Burly Public Cloud solutions and “encrypt files in your repo with gpg” there exists a pocket of utility for some very focused tooling.
Doppler is interesting because it solves the “where to put my secrets” problem and fleshes out the space a little bit more to fully encompass “managing potentially-sensitive key/values” at the product level.
I’m going to go in blind and see what it’s all about, and how Doppler gels with the types of tooling and development patterns that someone like myself is accustomed to.
Disclosure: Doppler contacted me about an opportunity to take their product for a spin, so I’m being compensated for writing up this experience. However, their developer relations team is honorable and “write up your experience” is the only direction they gave, so there won’t be any astroturfing here. Everything you’ll read is solely from my own mouth! Err, fingers.
Table of Contents
First Steps
Local Tooling
I don’t need to repeat the instructions provided by Doppler, but there are some interesting traits to note.
Over at Installing the Doppler CLI there’s plenty of packaging options, and I was frankly surprised that the CLI tool is present in nixpkgs!
I just sort of assume that vendor packaging will overlook esoteric ecosystems like the cadre of NixOS users that I’m a part of, but doppler is present in nixpkgs and even at the latest stable version.
Nice!
If you’re a nix user and on flakes, you can invoke the following to run doppler right now:
nix run 'github:NixOS/nixpkgs/nixpkgs-unstable#pkgs.doppler' -- --version
v3.38.0
Kudos to whoever is in charge of packaging and distribution here; nixpkgs is sort of the “last mile” when it comes to package repositories so the effort is appreciated.
SaaS Signup
Nothing excessively exciting here either. Again, I would consider myself an edge case user (developing on a Linux/NixOS desktop) but the signup process and coupling my account to the CLI was smooth. A few beats later and we’re ready to go (I used GitHub OAuth).
Figure 1: Initial Doppler landing page
The Illustrative Case(s)
The value proposition for Doppler is to easily manage environment variables at scale. I find that the best way for me to digest new tools is to start using them, so let’s give this a shot with some examples.
Wrapping Commands
The simplest case of “I need a secret” is probably shell commands that expect secrets from the environment.
We’re familiar with typical environment variables like VAULT_TOKEN or AWS_SECRET_ACCESS_KEY.
Assuming that we aren’t going whole-hog yet with a skeleton project and git repository, can we use doppler to arbitrarily inject env vars into commands when we need them?
Doppler relies on organizing values within Projects, so let’s try making a general-purpose one:
shelldoppler projects create shells
┌────────┬────────┬─────────────┬──────────────────────────┐│ ID │ NAME │ DESCRIPTION │ CREATED AT │├────────┼────────┼─────────────┼──────────────────────────┤│ shells │ shells │ │ 2022-03-22T22:08:16.069Z │└────────┴────────┴─────────────┴──────────────────────────┘
Look at that ASCII table. Lovely. What’s in there?
shelldoppler --project shells --config dev secrets
┌─────────────────────┬────────┐│ NAME │ VALUE │├─────────────────────┼────────┤│ DOPPLER_CONFIG │ dev ││ DOPPLER_ENVIRONMENT │ dev ││ DOPPLER_PROJECT │ shells │└─────────────────────┴────────┘
Ah, a lot of informational environment variables. Cool.
Note: In addition to organizing environment variables by project, Doppler further segments these values into a “config”, (i.e., development, production, staging). We’ll use the default “development” config for now.
Okay.
One of the all-time most common uses that I’ve had personally is interacting with AWS over the command line.
The overly-verbose environment variables AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY are the default environment variables that aws will search out in order to authenticate against the AWS API.
Let’s give it a shot!
Fortunately the CLI docs are helpful enough to the extent that I don’t need to leave the terminal:
shelldoppler secrets set --help
Set the value of one or more secrets.There are several methods for setting secrets:1) stdin (recommended)$ echo -e 'multiline\nvalue' | doppler secrets set CERT2) interactive stdin (recommended)$ doppler secrets set CERTmultilinevalue<snip>
Neato. Currently these values are set in my shell, so let’s get them into Doppler first.
shellecho $AWS_ACCESS_KEY_ID | doppler --project shells --config dev secrets set AWS_ACCESS_KEY_ID
shell┌───────────────────┬──────────────────────┐│ NAME │ VALUE │├───────────────────┼──────────────────────┤│ AWS_ACCESS_KEY_ID │ AKIA.....<snip>..... │└───────────────────┴──────────────────────┘
echo $AWS_SECRET_ACCESS_KEY | doppler --project shells --config dev secrets set AWS_SECRET_ACCESS_KEY
┌───────────────────────┬──────────────────────────────────────────┐│ NAME │ VALUE │├───────────────────────┼──────────────────────────────────────────┤│ AWS_SECRET_ACCESS_KEY │ .................<snip>................. │└───────────────────────┴──────────────────────────────────────────┘
All right. Let’s peek at the “shells” project in the Doppler dashboard because I’m curious about what that looks like now:
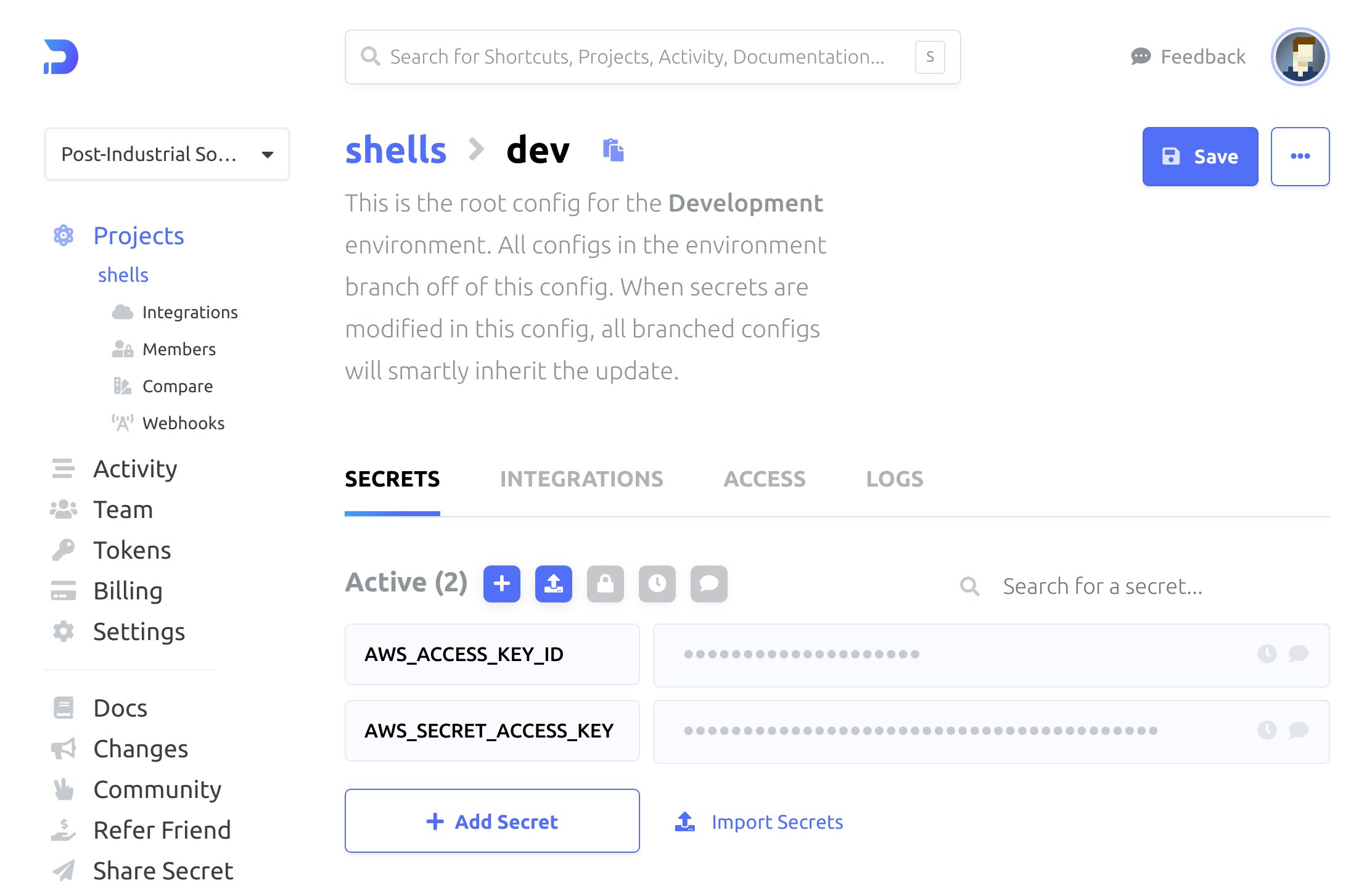
Figure 2: Shells project secrets
Everything seems right!
To ensure I’m working in a naked shell, we can either open a new terminal or unset the old variables, either way (with unset AWS_ACCESS_KEY_ID AWS_SECRET_ACCESS_KEY).
Now to try injecting these values at runtime.
First, a failing test - to ensure that awscli really can’t find credentials that I need.
aws s3 ls s3://blog-tjll-net
Unable to locate credentials. You can configure credentials by running "aws configure".
Sackcloth and ashes; no AWS access. As expected.
“Wrapping” commands in doppler run appears to be a first-class citizen, so let’s try this out:
doppler --project shells --config dev run -- aws s3 ls s3://blog-tjll-net | tail -n3
2015-02-15 01:13:39 286 humans.txt2022-02-04 12:02:08 8548 index.html2015-02-15 01:13:39 107 robots.txt
Nice!
I store the blog in S3, so this these files aren’t secret, but interacting with them over the S3 API is a privileged operation.
It certainly seems like the doppler run use case isn’t hard to get running with.
I mentioned at the beginning of this post that Doppler seems to sit between “DIY in your own encrypted repository” and “go all-in with something like a KMS service”.
At least in my modern development workflow, I never commit sensitive information directly to disk, and values like API keys are either encrypted or fetched on the fly when needed.
This seems to fill that niche fairly well, and as a bonus, the Doppler docs even support direnv as a first-class citizen, which is hugely convenient - I lean on direnv heavily for this exact sort of thing, so we can even codify the doppler run semantics (we need to use the download positional argument) in a top-level .envrc so the secrets are fetched transparently.
Check it:
cat .envrc
export $(doppler --project shells --config dev secrets download --no-file --format env-no-quotes)
And the environment gets populated. Again, a common workflow that I’m glad is supported.
Projects
That covers what injecting arbitrary values looks like, but I’m also curious about the more fully-fledged, project-oriented, multiple-environment scenarios that accompany typical software development and deployment. Whether this takes the form of a program that hits an API or consumes some sort of token, we’re likely to need some sort of method to slip in these dynamically-fetched values.
As an illustrative case, let’s build a toy application that relies on an API that requires a token. Full speed ahead!
Bedrock
For this micro-project we’ll use python’s flask library to make an application that tells us about the weather. It’s boring! Which is a good thing, in this case. We’re concerned with getting familiar with how Doppler works and not necessarily the myriad other bits and pieces of the python ecosystem.
Let’s call our project cloudler because it blends The Cloud, weather, and Doppler in a particularly obnoxious way:
mkdir cloudler
cd !$
git init
If you’re in a typical development environment, I’ll assume that you can get your necessary prerequisites installed. If you’re like me and use nix heavily, here’s some files I got started with:
shellcat flake.nix
- Font used to highlight punctuation characters.
- Font used to highlight constants and labels.
- Font used to highlight variable references.
- Font used to highlight keywords.
- Font used to highlight function calls.
- Font used to highlight property references. For example, property lookup of fields in a struct.
- Font used to highlight type and class names.
- Font used to highlight variable names.
- Font used to highlight function names.
- Font used to highlight strings.
- Font used to highlight properties of an object. For example, the declaration of fields in a struct.
{
description = "a flake";
inputs.nixpkgs.url = "github:NixOS/nixpkgs/nixpkgs-unstable";
inputs.flake-utils.url = "github:numtide/flake-utils";
inputs.devshell-flake.url = "github:numtide/devshell";
outputs = { self, nixpkgs, flake-utils, devshell-flake }:
flake-utils.lib.eachDefaultSystem (system: let
pkgs = import nixpkgs {
inherit system;
config = { allowUnfree = true; };
overlays = [ devshell-flake.overlay ];
};
in with pkgs; rec {
packages = {
cloudler = with python3Packages; buildPythonApplication {
pname = "cloudler";
version = "1.0.0";
src = ./.;
propagatedBuildInputs = [
doppler requests flask
];
};
container = dockerTools.buildLayeredImage {
name = "cloudler";
tag = packages.cloudler.version;
created = "now";
contents = [ cacert packages.cloudler ];
config.Cmd = [
"${doppler}/bin/doppler"
"run"
"--"
"${packages.cloudler}/bin/app.py"
];
};
};
defaultApp = packages.cloudler;
defaultPackage = packages.cloudler;
devShell = devshell.mkShell {
packages = [
packages.cloudler flyctl httpie doppler cowsay
(python3.withPackages (p: with p; [
requests flask
]))
];
};
});
}
cat .envrc
use flakeshell
cat setup.py
- Font used to highlight strings.
- Font used to highlight keywords.
from setuptools import setup, find_packages
setup(
name='cloudler',
version='1.0.0',
packages=find_packages(),
scripts=["app.py"],
)
git add flake.nix .envrc setup.py
direnv allow
which python
/nix/store/nrx2jhajrgxplg8x4j3mwm9hhc8z5m0g-devshell-dir/bin/python
In case you’re not a nix devotee: these files set up a sandboxed shell in cloudler/ that installs python with the libraries I need, httpie for ad-hoc API testing, and the doppler CLI tool as well, so we’re guaranteed to have everything we need.
It also defines the build steps to generate a Docker container, which we’ll use as our deployment artifact later.
If you’re playing along at home and don’t use nix, you can achieve similar results with a simple Dockerfile.
Let’s get cookin’!
Validation
To begin, let’s first interact directly with the API we’re interested in. I signed up for an account with OpenWeatherMap and snagged an API key. Create a project in Doppler:
shelldoppler projects create cloudler
Now that we’re working in a proper project, we can configure doppler appropriately:
doppler setup
? Select a project: cloudler? Select a config: dev┌─────────┬──────────┬────────────────────────────┐│ NAME │ VALUE │ SCOPE │├─────────┼──────────┼────────────────────────────┤│ config │ dev │ /home/tylerjl/src/cloudler ││ project │ cloudler │ /home/tylerjl/src/cloudler │└─────────┴──────────┴────────────────────────────┘
Works as expected! Time to store our API key. Crucial to this workflow, I’m not persisting my API key any more spots than it needs to be to reduce risk of exposure. I copied my key out of the welcome email from OpenWeatherMap and into my clipboard and proceeded to:
shelldoppler secrets set API_KEY
…and follow the prompts.
Once our secret is saved, it’ll be available when we ask for it.
Let’s use a simple httpie command coupled with the secret we want to retrieve weather data:
http http://api.openweathermap.org/data/2.5/weather q==Boise appid==$(doppler secrets get --plain API_KEY)
<big blob of json>
I get a nice snapshot of the current weather. In a more readable form;
shellhttp http://api.openweathermap.org/data/2.5/weather q==Boise appid==$(doppler secrets get --plain API_KEY) | jq '.weather[].main'
"Clear"
We have an API endpoint, an API key, and now need to integrate the dynamic secret injection into a real application.
For a simple weather reporting application, we’ll create a very basic web app with Flask. Consider:
Python- Font used to highlight operators.
- Font used to highlight function names.
- Font used to highlight strings.
- Font used to highlight type and class names.
- Font used to highlight builtins.
- Font used to highlight variable names.
- Font used to highlight keywords.
- Font used to highlight comments.
#!/usr/bin/env python3
import os
import requests
from flask import Flask
app = Flask(__name__)
@app.route('/<city>')
def weather(city):
conditions = requests.get(
"http://api.openweathermap.org/data/2.5/weather",
params={
'q': city,
'appid': os.environ.get('API_KEY')
}
).json()
return f"The weather is {conditions['weather'][0]['main']}!"
if __name__ == '__main__':
app.run(host='0.0.0.0')
This returns a very simple plaintext response with the weather in a given city.
Per the python Doppler docs, there isn’t (currently) a native integration/library for python, so this application assumes that it’ll yank the credentials out of the environment.
We’ll get hit with a HTTP 401 if we send requests without an appid parameter so we better include it!
Fortunately, that ends up looking pretty simple in practice:
shelldoppler run -- flask run
* Environment: productionWARNING: This is a development server. Do not use it in a production deployment.Use a production WSGI server instead.* Debug mode: off* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
How about sending requests to OpenWeatherMap with our API key?
shellhttp :5000/Boise | cowsay
_______________________< The weather is Clear! >-----------------------\ ^__^\ (oo)\_______(__)\ )\/\||----w ||| ||
That’s great, and it works as expected.
Per the previous paragraphs, we can actually make the doppler invocation automatic and transparent by leveraging direnv:
cat .envrc
use flakeshell
export $(doppler secrets download --no-file --format env-no-quotes)
direnv allow
flask run
Now we don’t even need to think about importing variables!
Deployment
This experimentation has been all well and good, but I’m equally interested in the deployment story with Doppler. Retrieving secrets as an actual human isn’t complicated in terms of trust, but if I want to grant a service account somewhere the ability to grab secrets from the environment, that’s a different matter. Morever, we can investigate differing behavior between development and production.
Remember my flake.nix?
I have flyctl present, so let’s bootstrap a quick project on Fly:
flyctl launch
I’ll answer the questions to create an app called cloudler in the sea region.
The subsequent fly.toml needs a few edits, so it ends up thusly:
app = "cloudler"
[env]
[build]
image = "cloudler:1.0.0"
[[services]]
internal_port = 5000
protocol = "tcp"
[[services.ports]]
force_https = true
handlers = ["http"]
port = 80
[[services.ports]]
handlers = ["tls", "http"]
port = 443
This next part is crucial: our docker image is wrapping the python application within doppler run, so we need to inject the Doppler service token into the application process.
We can do that cleanly:
flyctl secrets set DOPPLER_TOKEN=$(doppler configs tokens create fly-io --plain)
I’m particularly proud of the fact that we never even see the token first-hand; it just gets generated by Doppler and seamlessly slipped into flyctl without any intermediate steps.
Ready to launch?
Using our flake.nix, we’ll build and load the container image, then ask flyctl to roll it out:
nix build '.#container'
docker load < result
flyctl deploy
Oh buddy.
Is that all there is to it?
Wait a beat for flyctl deploy to resolve and then try the generally-available endpoint.
http https://cloudler.fly.dev/Adelaide | cowsay
________________________< The weather is Clouds! >------------------------\ ^__^\ (oo)\_______(__)\ )\/\||----w ||| ||
That is all there is to it!
Our API key is being dynamically populated via doppler run inside the running container on Fly.
All is right with the world.
From everything I’ve seen, the doppler run wrapper is pretty transparent and there’s no interruption in log flow from flyctl logs.
I’ve experienced issues in the past with other methods that buffer either stdout or stderr so that’s an important consideration using this approach.
Conclusion
Judging from the Doppler documentation, there’s a fair number of features that I haven’t kicked the tires on. In particular, “branch configs” seem interesting from the perspective of juggling many variables that might otherwise become tangled in a maze of different environments. That and some public cloud integrations (such as for AWS) are almost certainly a few layers of abstraction above just populating the environment variables for a running process, though that operational method is more than sufficient for lots of applications. Injecting an environment variable should work anywhere regardless of your platform of choice.
My take-away opinion is that there’s certainly some good niches this fills. If we start from the baseline precaution of “commit encrypted files” to a repository there are a number of undesirable tradeoffs (forward secrecy, plaintext values on-disk following decryption, and so on). I’ve typically operated one level up by running my own personal Vault deployment, but if we liken Vault to a operational primitive like a programming language’s implementation of a data structure, then Doppler is the higher level abstraction that gels a little more smoothly with the needs of a software development team - native support for different environments, cloud integrations, and handling the intricacies about how principals are authenticated against the secret store.
So there you have it. It does what is says on the box, is widely available, and works as expected in my most common workflows; namely, shell tools and running containers in production. I appreciate the folks at Doppler for funding this experiment and offer them a virtual high-five to a positive experience and promoting the “never expose secrets” mindset with their tooling.